Introduction
Decision tree is one of the most widely used machine learning algorithms in practice due to its being easy to understand and implement and more importantly, the output prediction is understandable. Decision tree is a non-parametric algorithm that can be used for both classification and regression problems [1]. The assumption of the decision tree algorithm is similar to k-nearest neighbors whereby data points are not randomly distributed in the feature space. Instead, data points belonging to a class tend to be close to each other, thus, appearing in clusters. K-nearest neighbors algorithm simply stores the training instances to perform predictions. Although the k-nearest neighbors algorithm is simple and can be powerful, it is memory intensive and computationally inefficient especially when the training set is large. Furthermore, what we are interested in is only the prediction. Consider a classification problem of YES and NO. If a test point falls in a cluster of YES, we will be able to immediately know that the test point belongs to YES before we calculate the distances. Therefore, the distance calculation is not really needed if the regions of YES and NO have been defined and we know in which region the test points fall.
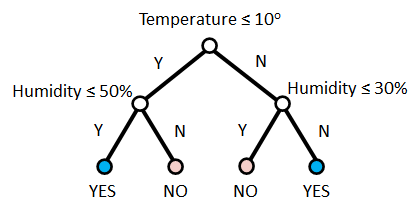
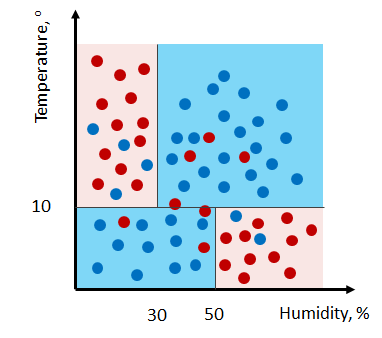
This idea is implemented in the decision tree algorithm. The decision tree algorithm does not store the training data. Instead, the training data is used to build a tree structure consisting of decision nodes and leaf nodes that divides that feature space into regions of similar labels. Consider a tree structure and its classification regions in Figure 1. The first node in the tree structure is the root node, which represents the whole training set which consists of two input features, Temperature,  and Humidity,
and Humidity,  and two labels, YES and NO. This root node represents the first split whereby the training set is split along one dimension (Temperature) by defining a split-point or a threshold at
and two labels, YES and NO. This root node represents the first split whereby the training set is split along one dimension (Temperature) by defining a split-point or a threshold at  . The split results in two sets of instances, one with all instances with
. The split results in two sets of instances, one with all instances with  and the others with at
and the others with at  . Then, the region is split along at and the region
. Then, the region is split along at and the region  is split along at
is split along at  . The decision tree has three decision nodes including the root node, which represent the condition for each feature split. The result of this process produces two regions representing the two labels indicated by the last four nodes known as the leaf nodes. Thus, in decision tree, we just need to store the conditions of the split and the labels. Given a test point, a decision tree performs the prediction by evaluating the test point against the condition of each nodes and traversing through the true branches until it reaches a leaf node. For example, given a test input
. The decision tree has three decision nodes including the root node, which represent the condition for each feature split. The result of this process produces two regions representing the two labels indicated by the last four nodes known as the leaf nodes. Thus, in decision tree, we just need to store the conditions of the split and the labels. Given a test point, a decision tree performs the prediction by evaluating the test point against the condition of each nodes and traversing through the true branches until it reaches a leaf node. For example, given a test input  . The condition of the root node is false (
. The condition of the root node is false ( ). Thus we take the right branch and the following condition is false (
). Thus we take the right branch and the following condition is false ( ). The right branch is taken and the input is predicted as YES.
). The right branch is taken and the input is predicted as YES.
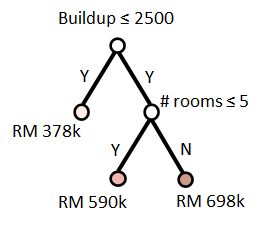
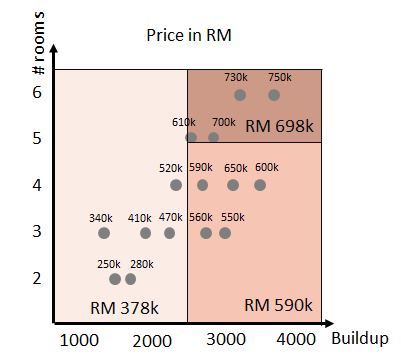
Decision tree algorithm can be used for regression problems. Since the predicted value is a numerical value, the leaf nodes represent the mean of the responses of the instances in the regions. Consider a tree structure and its regression regions in Figure 2. The predicted values are estimated by the mean of the responses in the regression regions.
Building a Tree
The accuracy of the prediction depends on where the split-point is defined for each decision node. To find the optimal split, we measure the reduction in randomness or uncertainty after the feature is split. The reduction in randomness is known as information gain. The information gain of splitting the set or node  along feature,
along feature,  at a split-point,
at a split-point,  is given as follows:
is given as follows:

where  and
and  are the nodes (sets) of the left region (branch) and right region (branch) respectively after splitting at split-point .
are the nodes (sets) of the left region (branch) and right region (branch) respectively after splitting at split-point .  is the fraction of instances in branch
is the fraction of instances in branch  .
.  is the impurity function which measures quality of split or the homogeneity of the labels in set .
is the impurity function which measures quality of split or the homogeneity of the labels in set .
Classification
In the classification setting, there are two commonly used impurity functions which are entropy and gini. Entropy measures the uncertainty of the feature set. Entropy function is defined as follows:

where  is the number of class labels,
is the number of class labels,  is the probability of selecting an instance of class
is the probability of selecting an instance of class  in node .
in node .
Gini measures the probability of a randomly chosen instance to be wrongly labeled. Gini function is defined as follows:

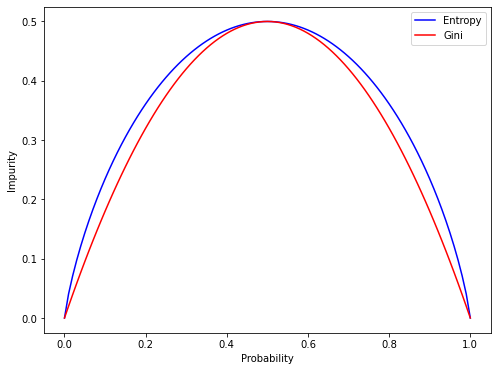
where is the number of class labels, is the probability of selecting an instance of class in node . For two classes, the node impurity is maximum when the subsets have an equal number of instances in which the probability of both classes is 0.5 as shown in Figure 3.
Numerical Example
Consider the following split as shown in Figure 4. Calculate the entropy and gini measures and the information gain.
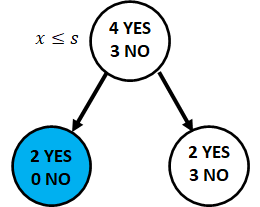
Information gain of the split with entropy measure




Information gain of the split with gini measure
![H(t)=1-[(\frac{4}{7})^2 + (\frac{3}{7})^2]=0.4898](http://halimnoor.com/wp-content/ql-cache/quicklatex.com-155990ad0490a01906d5a334ab0385e5_l3.png "Rendered by QuickLaTeX.com")
![H(t_l)=1-[(\frac{2}{2})^2 + (\frac{0}{2})^2]=0.0](http://halimnoor.com/wp-content/ql-cache/quicklatex.com-686993d422e0030b335f692644c39089_l3.png "Rendered by QuickLaTeX.com")
![H(t_r)=1-[(\frac{2}{5})^2 + (\frac{3}{5})^2]=0.4800](http://halimnoor.com/wp-content/ql-cache/quicklatex.com-8d778bde1d0019838cb2e8809f80ca56_l3.png "Rendered by QuickLaTeX.com")

Regression
In the regression setting, the impurity is measured by the sum of squared errors. The sum of squared errors is defined as follows:

where  is the response of
is the response of  th instance and
th instance and  is the mean response.
is the mean response.
Numerical Example
Consider the following data. Calculate the information gain if the  is split at 2010 (
is split at 2010 ( )
)






Algorithm
Based on the information gain equation above, the optimal split can be achieved when the sum of impurity of both branches is minimum (minimum uncertainty in both branches). Therefore, the problem of finding the optimal split can be viewed as finding the best feature and the best split-point for that feature which maximizes the information gain. This can be expressed as follows:

where  is the number of input features,
is the number of input features,  is the set of possible split-points for feature . For numerical features, the set of possible split-points can be obtained by sorting the unique values of
is the set of possible split-points for feature . For numerical features, the set of possible split-points can be obtained by sorting the unique values of  . For categorical features, the set of possible thresholds is replaced with the set of feature labels. The algorithm to build a decision tree is given below. The algorithm builds a decision tree with leaf nodes composed of one class or pure (instances in the node belong to the same class).
. For categorical features, the set of possible thresholds is replaced with the set of feature labels. The algorithm to build a decision tree is given below. The algorithm builds a decision tree with leaf nodes composed of one class or pure (instances in the node belong to the same class).
repeat until all leaf nodes are pure:
 compute
compute  where
where 
 split node at
split node at Pruning a Tree
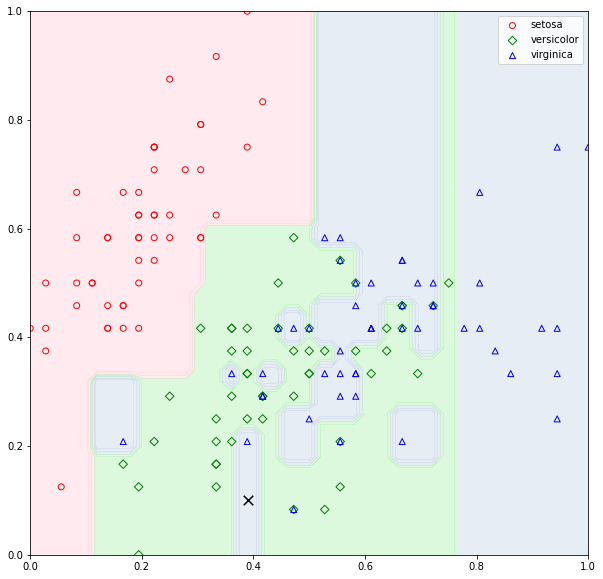
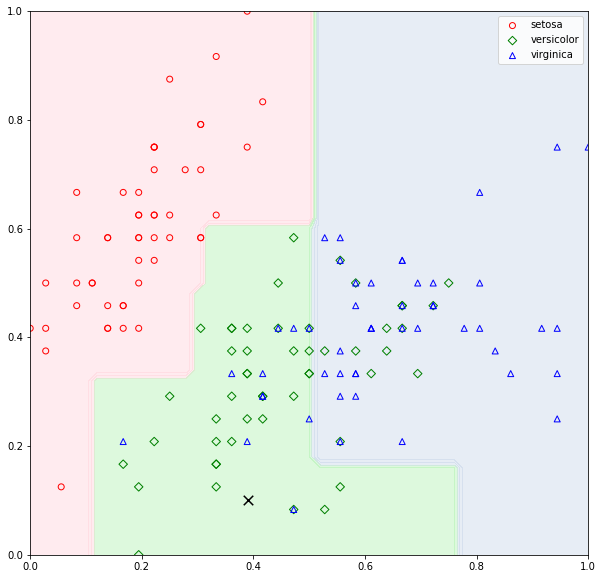
The algorithm builds a decision tree with zero error (misclassification) because it will keep on splitting until all the nodes are composed of one class (pure leaf nodes). This may cause overfitting (the model to overfit the data). Figure 3 illustrates a decision tree classifier fitted with the iris dataset. As can be seen in the figure, the decision surface shows a few blue regions with a single data point. These decision boundaries are induced due to the algorithm continues splitting until all leaf nodes are pure. Consider a test point indicated by the black cross in Figure 4. The test point will be classified as VIRGINICA although the test point falls in the region where the majority of the data points belong to VERSICOLOR. To prevent overfitting when building the tree, we can limit the number of splits in the tree structure which is known as pruning. In general, there are two approaches to tree pruning: pre-pruning and post-pruning.

Pre-pruning
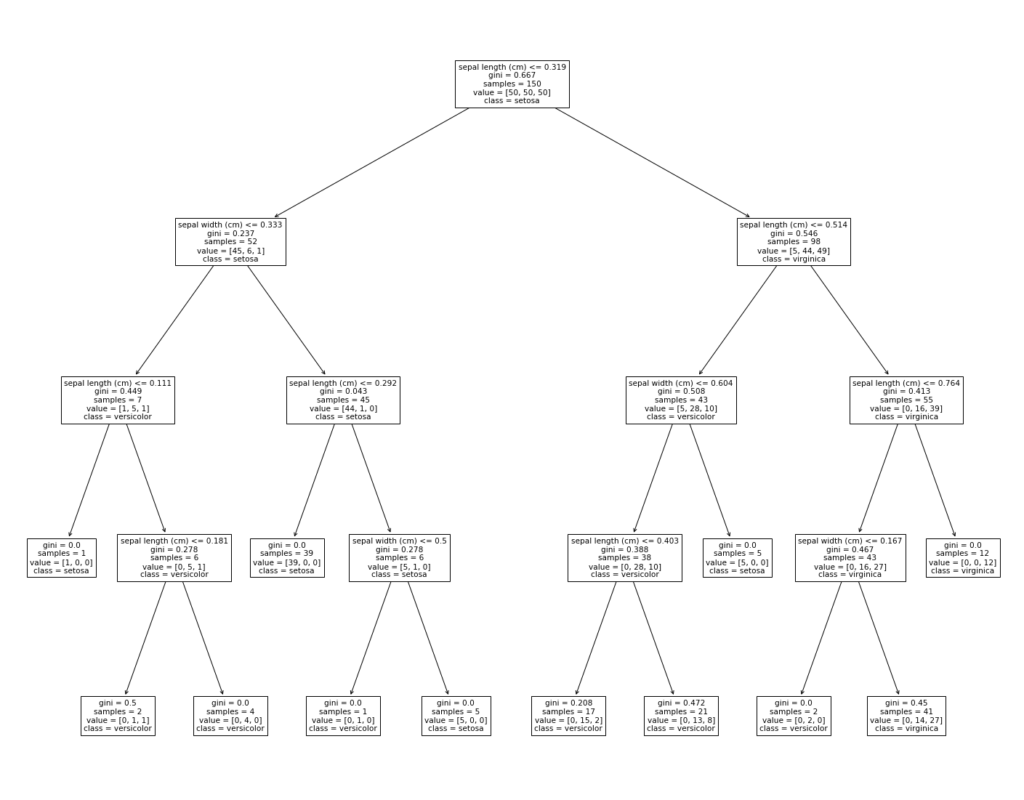
In pre-pruning, we stop the tree-building process if the information gain of the split does not exceed a certain threshold. The threshold value is defined to justify the splitting of the node. In this way, the tree will not grow too large. We can also specify the maximum depth of the tree structure. The depth of the tree is defined by the maximum distance from the root node to a leaf node. Other common parameters that can be defined are the minimum number of instances required to split the node, the minimum number of instances to be a leaf and the maximum number of leaf nodes. Figure 5 shows a pruned decision tree by specifying the maximum depth to 4. The distance is counted by the number of paths from the root node to a leaf node. The decision boundaries of the tree are shown at the bottom of the figure. Although pre-pruning can prevent overfitting, fine-tuning the parameters is difficult and sometimes the obtained model is not optimal.
Since the algorithm of building the tree is stopped before the misclassification rate is zero, some of the leaf nodes will not be pure. How do we assign which class to a leaf node? The leaf nodes are assigned to the class with the majority instances. For example, if leaf node composed of 5 instances belong to POSITIVE class and 2 instances belong to NEGATIVE class. Node will be assigned to POSITIVE class. The classification of a test point is given as follows:

where  is predicted probability of class given the test point which is based on the proportion of instances belong to class in node . The probability of misclassification of leaf node is
is predicted probability of class given the test point which is based on the proportion of instances belong to class in node . The probability of misclassification of leaf node is

Post-pruning
The post-pruning is to let the tree grow until the error rate is zero (full tree). Then, the size of the tree is reduced by removing the insignificant branches. This is known as cost-complexity pruning. In this method, we prune the tree by considering the error rate of the tree and the complexity of the tree. The tree complexity is defined as the number of leaf nodes. The higher the number of leaf nodes, the higher the complexity because the tree has more possibilities in partitioning the training set.
Specifically, the pruning method is governed by the cost-complexity measure. The function is to be minimized while pruning the tree. The function is given as follows:

where  is the tree complexity,
is the tree complexity,  is the complexity parameter.
is the complexity parameter.  is the error rate of tree
is the error rate of tree  which is defined as follows:
which is defined as follows:

where  is the probability of misclassification of leaf node .
is the probability of misclassification of leaf node .  where
where  is number of instances in node and
is number of instances in node and  is the total number of instances.
is the total number of instances.
favors a larger tree because a large tree minimizes the error rate while  favors a smaller tree because a small tree minimizes the complexity of that tree.
favors a smaller tree because a small tree minimizes the complexity of that tree.
The complexity parameter governs the trade-off between the tree’s error rate and complexity. A large value of results in a smaller tree while a small value of results in a larger tree.
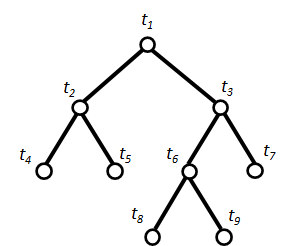
How do we determine which nodes are insignificant? Consider a tree structure in Figure 6. We look at any decision node and its two leaf nodes e.g. node  and its two descendants,
and its two descendants,  and
and  . If the reduction in error when splitting is not significant, prune and and becomes the leaf node.
. If the reduction in error when splitting is not significant, prune and and becomes the leaf node.
Now, how do we evaluate the reduction in error? Based on the cost-complexity function, we can define the cost-complexity of a node, as follows:

For any node , in general, the error rate of its branch  is less than or equals to its node.
is less than or equals to its node.

where  . For example, consider node , the sum of error rate of and is less than or equals to the error of . Notice that the expression is parameterized by . We know that when is sufficiently small, is true. Therefore, if we choose a higher , we will be able to know which decision node is the weakest link.
. For example, consider node , the sum of error rate of and is less than or equals to the error of . Notice that the expression is parameterized by . We know that when is sufficiently small, is true. Therefore, if we choose a higher , we will be able to know which decision node is the weakest link.
We can rewrite as follows:

Solving for yields

The weakest link in a tree is

where is the error rate of tree ,  is the error rate of node and is the number of leaf nodes in .
is the error rate of node and is the number of leaf nodes in .
Therefore, a decision node with the lowest is the weakest link and its branch should be pruned. Then, the process is repeated on the pruned tree, until there is only the root node. By the end of this procedure, we have many subtrees. The optimal tree is selected among the subtrees using a validation set or cross-validation.
Numerical Example
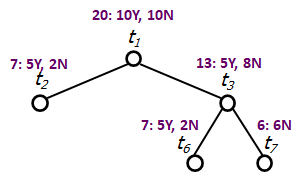
Consider a tree structure in Figure 7. The training set consists of 10 instances belonging to YES and 10 instances belonging to NO.
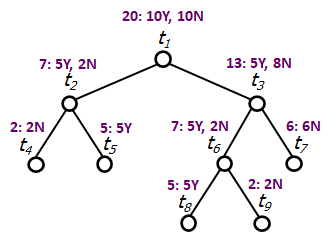
Node 

 (all leaf nodes are pure)
(all leaf nodes are pure)

Node 

 (all leaf nodes are pure)
(all leaf nodes are pure)

Node 

 (all leaf nodes are pure)
(all leaf nodes are pure)

Node

 (all leaf nodes are pure)
(all leaf nodes are pure)

Cost-complexity measure for each node.




is minimum, hence we prune and ( has fewer instances than ). The subtree  is given in Figure 8.
is given in Figure 8.
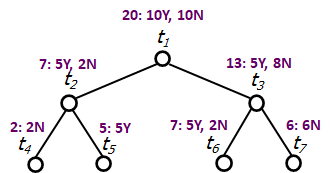
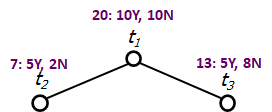
Node
 (all leaf nodes are pure)
(all leaf nodes are pure)

Node
(all leaf nodes are pure)
Node
 (all leaf nodes are pure)
(all leaf nodes are pure)

Cost-complexity measure for each node.
is minimum, hence we prune  and
and  . The subtree
. The subtree  is given in Figure 9.
is given in Figure 9.
Repeat the computation for each node.
Cost-complexity measure for each node.


is minimum, hence we prune and  ( has fewer instances than ). The subtree
( has fewer instances than ). The subtree  is given in Figure 10.
is given in Figure 10.
Repeat the computation for each node.
Cost-complexity measure for each node.
We prune and (there is only one node).
For each subtree, we evaluate their performance using a validation set or cross-validation. The optimal tree is the one with the highest accuracy or lowest error.
References
[1] L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone, Classification And Regression Trees. New York: Routledge, 2017. doi: 10.1201/9781315139470.