Introduction
Principal component analysis projects the data in the directions of maximum variance. However, in some cases, maximizing the variance of the data may not achieve highly discriminative features. Fisher’s Linear discriminant analysis (LDA) is also a projection-based method that seeks to find a vector that defines the projection direction of the data [1]. Unlike principal component analysis which maximizes the variance of the data [2], linear discriminant analysis uses the labels of the data and projects the data in the direction that maximizes the separation of the classes as shown in Figure 1.
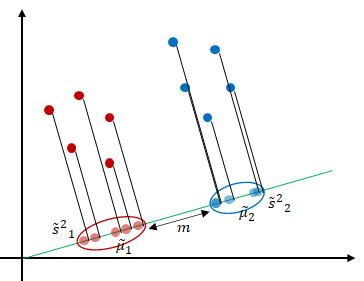
How do we find the projection that maximizes the class separation of the data? LDA states that maximum separation is achieved when the distance between the two clusters is maximum (or far away from each other). We consider the classification of two classes first, then generalize to more than two classes.
Binary Class LDA
Let  and
and  denote the means of data after projection which belong to class RED and BLUE respectively.
denote the means of data after projection which belong to class RED and BLUE respectively.

Furthermore, let  and
and  denote the scatters (variances) of data after projection which belong to class RED and BLUE respectively.
denote the scatters (variances) of data after projection which belong to class RED and BLUE respectively.



To ensure maximum class separation, we want the means to be far away from each other and the projected data in the clusters to be close to each other. In other words, we want the mean difference  to be large and the summation of the scatter
to be large and the summation of the scatter  to be small. Therefore, the objective is to maximize
to be small. Therefore, the objective is to maximize

The numerator can be expressed as

where  is between-class scatter matrix.
is between-class scatter matrix.
The denominator can be expressed as

where  is within-class scatter matrix.
is within-class scatter matrix.
Therefore, the objective function is

Taking the derivative and setting it equal to zero.

Given that  is a scalar, the expression becomes
is a scalar, the expression becomes

where  is the eigenvector of
is the eigenvector of  and
and  is the corresponding eigenvalue.
is the corresponding eigenvalue.
Multi-class LDA
When there are more than two classes, the between-class scatter matrix is defined as

where  and
and  is the global (overall) mean.
is the global (overall) mean.
The within-class scatter matrix is defined as

where  .
.
The number of components is defined as follows:

where  is the number of classes.
is the number of classes.
Solving for Eigenvector and Eigenvalue
Compute  and
and  .
.
Compute  .
.
 where
where  is an identity matrix.
is an identity matrix.
Solve  to obtain .
to obtain .
Substitute into  to obtain .
to obtain .
Numerical Example
Consider the following dataset









Find by solving where is an identity matrix.




 and
and 
Substitute 




Let  , thus
, thus 

References
[1] R. A. Fisher, “The Use of Multiple Measurements in Taxonomic Problems,” Annals of Eugenics, vol. 7, no. 2, pp. 179–188, 1936, doi: 10.1111/j.1469-1809.1936.tb02137.x.
[2] A. M. Martinez and A. C. Kak, “PCA versus LDA,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no. 2, pp. 228–233, Feb. 2001, doi: 10.1109/34.908974.