Introduction
Supervised learning is the most commonly used approach to machine learning. Some of the popular supervised learning applications are e-mail spam detection, optical character recognition and face recognition. In supervised learning setting, we are given a labeled dataset or in other words, the dataset comes in pairs of  , where
, where  and
and  is the number of samples or instances in the dataset. Each input
is the number of samples or instances in the dataset. Each input  is a
is a  -dimensional vector,
-dimensional vector,  where each element,
where each element,  is a feature describing the
is a feature describing the  -th input.
-th input.
Feature Vector
Let us consider a dataset consisting of patient data as shown in Figure 1. The dataset is arranged in the form of a table whereby the columns are the features of the patients. A row represents a patient. This is known as a structured data. The feature vector of th patient,  where feature
where feature  refers to th patient’s name,
refers to th patient’s name,  refers to th patient’s age,
refers to th patient’s age,  refers to th patient’s gender,
refers to th patient’s gender,  refers to th patient’s height, etc. The features can be categorical or numerical.
refers to th patient’s height, etc. The features can be categorical or numerical.

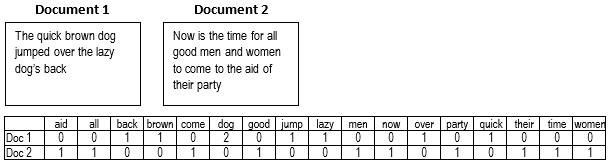
A dataset of text documents such as e-mails, review etc. Text data is typically converted into a form which can be used as input to the machine learning models. One of the commonly used methods to represent text data is the bag-of-words. The bag-of-words converts the text data into a sequence of integers based on the occurrence of the words in the document as shown in Figure 2. A bag-of-words feature vector, where is the number of words in the whole corpus, refers to the number of occurrence of word 1 in th document, refers the number of occurrence of word 2 in th document, etc.
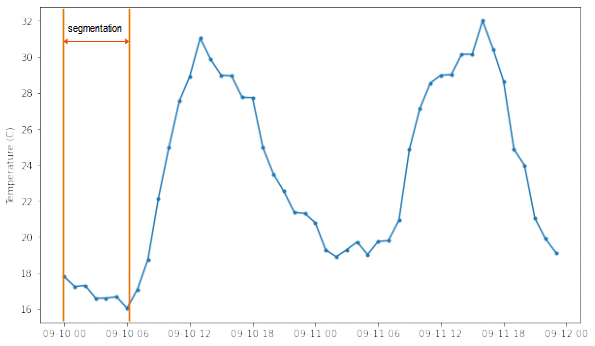
Time series data is a sequence of data that is ordered by time. For example, temperature sensors that are used to monitor the temperature of the environment generate measurements every 30 minutes. The sequence of the values over time is important because it contains information such as the trend and seasonality. A single sample (measurement) does not carry sufficient information to perform predictions. Therefore, for time series data, usually, we segment or group several samples, enough to contain the temporal information, and the segmentation is used for the prediction as shown in Figure 3. The subsequent segmentation may partially overlap the previous segmentation. The feature vector is a segmentation, where is the size of segmentation,  refers to
refers to  th sample in the th segmentation.
th sample in the th segmentation.
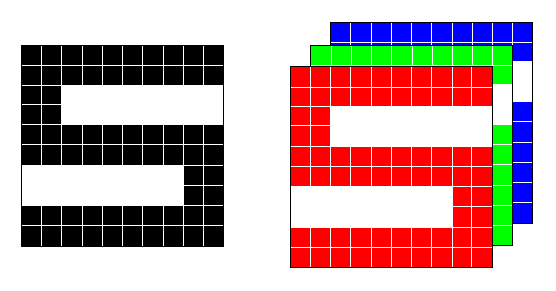
Finally, prediction with machine learning may involve image data. Image data is a collection of pixels arranged in rows and columns. The arrangement of the pixels defines the visual information or known as spatial structure. The image size determines the number of pixels. The image can be a grayscale image or a color image. For grayscale images, each pixel has one value representing the intensity of the pixel. The range of value is ![[0,255]](http://halimnoor.com/wp-content/ql-cache/quicklatex.com-0ad0c36a22c9516b1251af529b79c164_l3.png "Rendered by QuickLaTeX.com") whereby 0 represents black and 255 represents white. For color images, each pixel has three values for red, green and blue. The combination of the values defines the color of the pixel. The feature vector
whereby 0 represents black and 255 represents white. For color images, each pixel has three values for red, green and blue. The combination of the values defines the color of the pixel. The feature vector  where
where  ,
,  and
and  refer to red, green and blue of th pixel and is the number of pixels in the image.
refer to red, green and blue of th pixel and is the number of pixels in the image.
Types of Supervised Learning
The output or response variable  can be either a categorical or a numerical variable. If the output is a categorical variable, is a finite set,
can be either a categorical or a numerical variable. If the output is a categorical variable, is a finite set,  where
where  denotes the number of labels (classes) such as low, medium and high. This problem is known as multiclass classification. In the case of
denotes the number of labels (classes) such as low, medium and high. This problem is known as multiclass classification. In the case of  , say yes and no, the problem is known as binary classification. If the output is a numerical value,
, say yes and no, the problem is known as binary classification. If the output is a numerical value,  such as house price and salary, the problem is known as regression. The following table summarizes the types of supervised learning problems
such as house price and salary, the problem is known as regression. The following table summarizes the types of supervised learning problems
| Binary classification |  or or  | E.g. brain cancer detection (yes or no) |
| Multiclass classification |  where is the number of classes and where is the number of classes and  | E.g. classifying vehicles (lorry, van, car and motorcycle) |
| Regression |  | E.g. predicting house price, salary |
The data points are generated by an unknown function  . The aim of supervised learning is to approximate (learn) the unknown function
. The aim of supervised learning is to approximate (learn) the unknown function  given the dataset. With the approximated function, the output of a new data point
given the dataset. With the approximated function, the output of a new data point  can be predicted
can be predicted  . The approximated function is also called hypothesis or predictive model. Note that the two terms will be used interchangeably. To learn a function, we choose an algorithm such as decision tree, support vector machine or k-nearest neighbors – there are more algorithms. By choosing an algorithm, we are making an assumption about the data that we are trying to learn.
. The approximated function is also called hypothesis or predictive model. Note that the two terms will be used interchangeably. To learn a function, we choose an algorithm such as decision tree, support vector machine or k-nearest neighbors – there are more algorithms. By choosing an algorithm, we are making an assumption about the data that we are trying to learn.
Overfitting and Underfitting
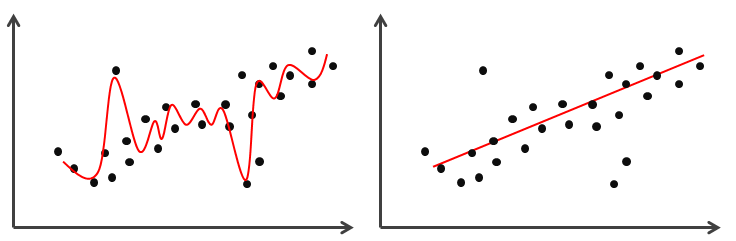
There are two problems that can be encountered when learning the hypothesis. The first problem is overfitting, whereby the hypothesis learns every minor variation in the data including the noise. This could easily happen when a highly flexible algorithm is used such as decision tree, support vector machine and neural network. Overfitting causes the hypothesis to become too specific, consequently failing to predict new data. Conversely, we do not want a hypothesis that failed to capture the variation in the data, which is known as underfitting. This could happen when a simple algorithm is used such as linear regression, logistic regression and linear discriminant analysis. The two problems are illustrated in Figure 5.
Loss Function
When approximating or learning the hypothesis  , we want a hypothesis that makes the least mistakes, which means the one with minimum incorrect classification or the best estimation. In machine learning, the mistakes or errors can be quantified using several loss functions. A loss function tells how bad a hypothesis is in performing the prediction.
, we want a hypothesis that makes the least mistakes, which means the one with minimum incorrect classification or the best estimation. In machine learning, the mistakes or errors can be quantified using several loss functions. A loss function tells how bad a hypothesis is in performing the prediction.
Zero-one loss
The simplest loss function, which typically used to quantify incorrect classification. The loss function calculates the summation of every misclassification and normalizes the summation by the number of instances. The zero-one loss is defined as follows:
 where
where 
Negative Log-Likelihood
Another loss function for classification problems is the negative log-likelihood or also known as cross-entropy. The loss function measures the difference between the probability distribution of the response and the prediction. For binary classification, the loss function is defined as follows:
![J_{nll}(\hat{f})= -\frac{1}{N} \sum_{i=1}^{N} [y^i \log_e{\hat{f}(\mathbf{x}^i)} + (1-y^i) \log_e{(1-\hat{f}(\mathbf{x}^i))}]](http://halimnoor.com/wp-content/ql-cache/quicklatex.com-45dfc622e5e24092f26c3da29081a952_l3.png "Rendered by QuickLaTeX.com")
For multiclass classification, the loss function is defined as follows:

Squared loss
The squared loss function is typically used to calculate the errors in regression problems. The loss function calculates the squared difference between the response and the predicted value and normalizes it by the number of instances. The squaring amplifies large prediction errors, thus encouraging the hypothesis not to make many mistakes. Conversely, if the prediction is close to being correct, the error will be very small, and little attention will be given to further improving the prediction.

Often, we build a set of hypotheses using different algorithms. This is crucial because there is no single algorithm that will always give the best performance for every problem. This is the No Free Lunch Theorem. Given the loss function, we choose a hypothesis, from a set of hypotheses  that minimizes the loss function.
that minimizes the loss function.

Performance Metrics
Besides the error, specifically in classification problems, we can evaluate the performance of the hypothesis by analyzing the number of correct and incorrect classifications in a specific table form called confusion matrix. Figure 6 shows a confusion matrix for a binary classification problem, where the two classes are “Yes” and “No”. The number of correctly classified of “Yes” class is represented by True Positive while the number of correctly classified of “No” class is represented by True Negative. The number of incorrect classifications are represented by False Negative and False Positive. False Negative is the number of instances belonging to “Yes” which are misclassified as “No”. False Positive is the number of instances belonging to “No” which are misclassified as “Yes”.
| Yes | No | |
| Yes | True Positive (TP) | False Negative (FN) |
| No | False Positive (FP) | True Negative (TN) |
Several performance metrics can be derived from the confusion matrix. Here we look at the four commonly used metrics. The first metric is called Recall. Recall is the fraction of relevant instances that are correctly classified. Recall is defined as follows:

The second commonly used metric is Precision. Precision is the fraction of relevant instances among the classified instances. Precision is defined as follows:

The F-score measure is derived from Recall and Precision as follows:

Lastly, the accuracy of the hypothesis is defined as follows:

For regression problems, the squared loss is typically used to evaluate the hypothesis. In addition to squared loss, absolute error is also used in model evaluation. The metrics are defined as follows:


The absolute difference between response and the predicted value is taken to avoid the canceling of positive and negative magnitude. The metric tells us how far the hypothesis prediction deviates from the response. Another commonly used performance metric is the  (
( -squared). measures the goodness of fit of the hypothesis. It measures the ratio of the hypothesis error to the worse or baseline error which is the average of the response. can be written as follows:
-squared). measures the goodness of fit of the hypothesis. It measures the ratio of the hypothesis error to the worse or baseline error which is the average of the response. can be written as follows:

where  is the sum of squared error of the hypothesis and
is the sum of squared error of the hypothesis and  is the sum of squared error of the baseline. The errors are defined as follows:
is the sum of squared error of the baseline. The errors are defined as follows:


where 
provides a measure in the range of 0 and 1.  indicates a perfect hypothesis while
indicates a perfect hypothesis while  indicates a worst possible hypothesis.
indicates a worst possible hypothesis.
Training, Validation and Test Sets
We not only want the hypothesis to perform well on the data that it has been trained to predict. Most importantly, the hypothesis must perform well on new data. The ability of the hypothesis to perform well on data that it has not seen before is known as generalization. To achieve generalization, the dataset is split into three subsets, namely training set, validation set and test set. This method is called hold-out method.
Hold-out Method
A portion of the data is hold-out for validation and evaluation. The training set will have a larger portion of the instances, typically around 60% – 80% of the dataset. The remaining instances are split into validation and test sets as shown in Figure 7. The dataset can also be split first into training and test sets. Then, the training set is further split into training and validation sets. The split ratio varies from one application or problem to another. The commonly used split ratio are 6:2:2, 7:1:2, 8:1:1.

The training set is used to learn the hypothesis. The machine learning algorithms have several parameters that need to be set and fine-tuned to obtain an optimal hypothesis. To find the optimal parameters, the validation set is used to validate the hypothesis. If the loss is too large, the hypothesis will be retrained with different parameters using the training set, and the newly trained hypothesis is validated using the validation set. Once, an optimal hypothesis is obtained, the test set is used to evaluate the performance of the hypothesis. The test loss is the generalization errors.
 -fold Cross Validation
-fold Cross Validation
Ideally, if we have sufficient data, a portion of instances can be set aside for validation. But data is often scarce and we don’t have sufficient training and validation instances to make a reliable estimate of the error. A popular method to solve this problem is cross-validation where the dataset is split into training and test sets. Then, the cross-validation is employed to train the hypothesis using the training set. We split the data into partitions of equal-sized, say  as shown in Figure 8.
as shown in Figure 8.
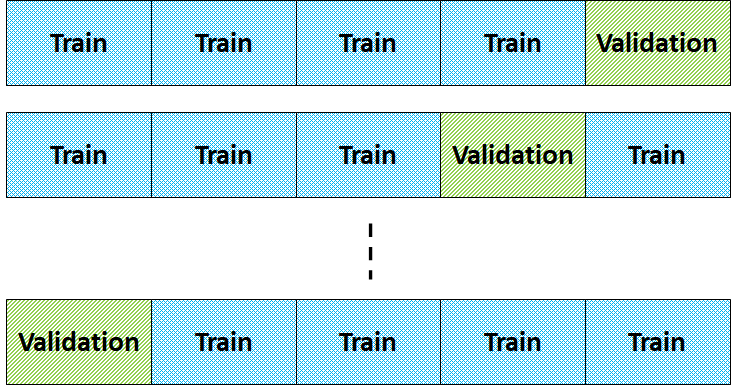
The hypothesis is learned using  partitions and the
partitions and the  th partition is used as the validation set. We repeat this for
th partition is used as the validation set. We repeat this for  and the error estimate is the average error over repetition. The common value of is 3, 5 and 10. When
and the error estimate is the average error over repetition. The common value of is 3, 5 and 10. When  , this is known as leave-one-out cross-validation whereby all instances except the th instance are used to learn the hypothesis.
, this is known as leave-one-out cross-validation whereby all instances except the th instance are used to learn the hypothesis.
Summary
In summary, the dataset is split into training set,  , validation set,
, validation set,  and test set,
and test set,  .
.
A set of hypotheses, are trained using the .

where  can be zero-one loss or squared loss.
can be zero-one loss or squared loss.
Choose a hypothesis that minimizes the validation loss.

where can be zero-one loss or squared loss.
Evaluate the chosen hypothesis,  on the test set and calculate the generalization error,
on the test set and calculate the generalization error,  .
.

where can be zero-one loss or squared loss.