Introduction
Perceptron is a parametric algorithm for solving binary classification problems whereby the label,  [1]. The assumption of perceptron is that data points are linearly separable. Specifically, we can define a hyperplane that can divide the feature space into regions and each region is labeled according to the classification. Although the assumption sounds simplistic, if data points belonging to a particular class have similar characteristics and are clustered together, the hyperplane can be defined between the clusters of the two classes to classify the data points.
[1]. The assumption of perceptron is that data points are linearly separable. Specifically, we can define a hyperplane that can divide the feature space into regions and each region is labeled according to the classification. Although the assumption sounds simplistic, if data points belonging to a particular class have similar characteristics and are clustered together, the hyperplane can be defined between the clusters of the two classes to classify the data points.
Essentially, given an input vector,  , the perceptron is a linear model that predicts the labels via
, the perceptron is a linear model that predicts the labels via

where  is the intercept also known as bias and
is the intercept also known as bias and  is the inner product between the model’s coefficient (or weight) vector and the input vector also known as linear combination of the inputs. We can introduce a constant input,
is the inner product between the model’s coefficient (or weight) vector and the input vector also known as linear combination of the inputs. We can introduce a constant input,  whose value is always 1. Then, the expression can be simplified as follows:
whose value is always 1. Then, the expression can be simplified as follows:

where  is the inner product in vector form.
is the inner product in vector form.
 is the sign function which returns
is the sign function which returns  if
if  is positive value and returns
is positive value and returns  if is negative value. Thus, given a test input,
if is negative value. Thus, given a test input,  , the classification of the input is given as follows:
, the classification of the input is given as follows:

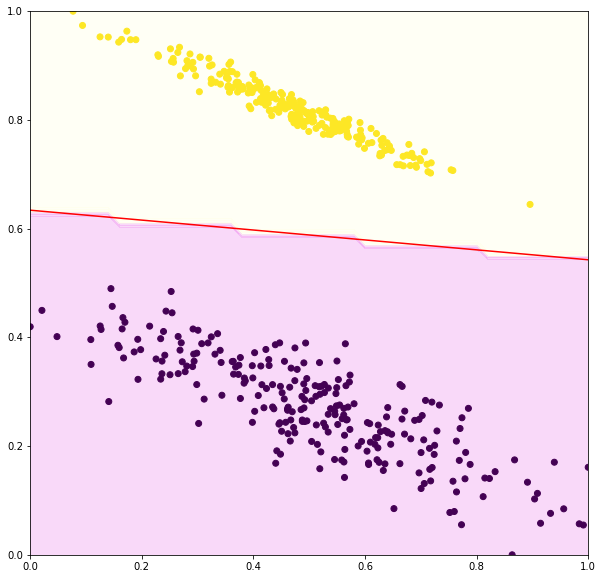
Consider a binary classification problem in Figure 1. The labels of the data points are YELLOW () and PURPLE (). A perceptron model is fitted to those data points. The decision boundary is defined by as indicated by the red line. The input space classified as is denoted by the orange shaded region while the purple shaded region denotes the input space classified as .
Numerical Example
Consider the perceptron model  . Predict the labels of the following inputs.
. Predict the labels of the following inputs.

 .
. 
 .
. 
 .
. 
 .
. 
Algorithm
As shown above, the weights,  define the hyperplane that separates the data points. The algorithm to find the optimal weights is given as follows:
define the hyperplane that separates the data points. The algorithm to find the optimal weights is given as follows:
initialize weights,
while  :
:
 for each (
for each ( ,
, ) in training set:
) in training set:
 if
if  :
:


First, the weights are initialized randomly. The algorithm keeps training until all instances are correctly classified. Thus, if the data is not linearly separable, the training will loop forever. For each iteration, error,  is initialized to zero, and the whole instances of the training set are classified and compared with their corresponding labels one by one. If the classification is incorrect, increment , and the weights are updated with values of element-wise multiplication
is initialized to zero, and the whole instances of the training set are classified and compared with their corresponding labels one by one. If the classification is incorrect, increment , and the weights are updated with values of element-wise multiplication  between the instance and the label. Otherwise, the weights are not updated.
between the instance and the label. Otherwise, the weights are not updated.
References
[1] F. Rosenblatt, “The Perceptron—a perceiving and recognizing automaton,” Cornell Aeronautical Laboratory, 1957.