Introduction
Boosting is an ensemble learning algorithm that combines many weak base models to produce a strong model. A weak model is a model that performs slightly better than random guessing. Thus, a weak model has an error rate that is slightly below 50%. The model could be any machine learning model such as a decision tree with a single split which is also known as decision stump. Unlike bagging models which consist of independent base models, boosting method sequentially builds the base models in which the models are trained based on the predictions of the previous models. We describe boosting in general first. The following sections present two popular boosting algorithms, adaptive boosting and gradient boosting.
Generally, a boosting model takes the form

where  is the weight of base model
is the weight of base model  . The ensemble model is built in an iterative manner whereby at iteration , we add base model
. The ensemble model is built in an iterative manner whereby at iteration , we add base model  to the ensemble model. The final prediction is obtained by evaluating all the base models and taking the weighted sum.
to the ensemble model. The final prediction is obtained by evaluating all the base models and taking the weighted sum.
The training is an iterative process whereby base models are added sequentially to the ensemble boosting model. At each iteration , the base model and its corresponding optimal weight are solved and added to the ensemble, and this process is repeated for  base models.
base models.

Typically, the optimal base model of each iteration is trained by minimizing a loss function.

where  is the loss function such as the squared loss and negative log-likelihood.
is the loss function such as the squared loss and negative log-likelihood.
Adaptive Boosting
Adaptive boosting, or simply AdaBoost [1] sequentially trains the base models on weighted training instances in which the weights are also sequentially modified to indicate the importance of the instances in the training process. Initially, the instances have equal weights. In the following iteration, the weights of the instances are individually updated based on the predictions of the base model. Those instances that were incorrectly predicted have their weights increased, while the instances that were correctly predicted have their weights decreased. Thus, the weights of the instances that are difficult to predict correctly will be ever-increased as iterations proceed, forcing the subsequent base models to focus on those instances.
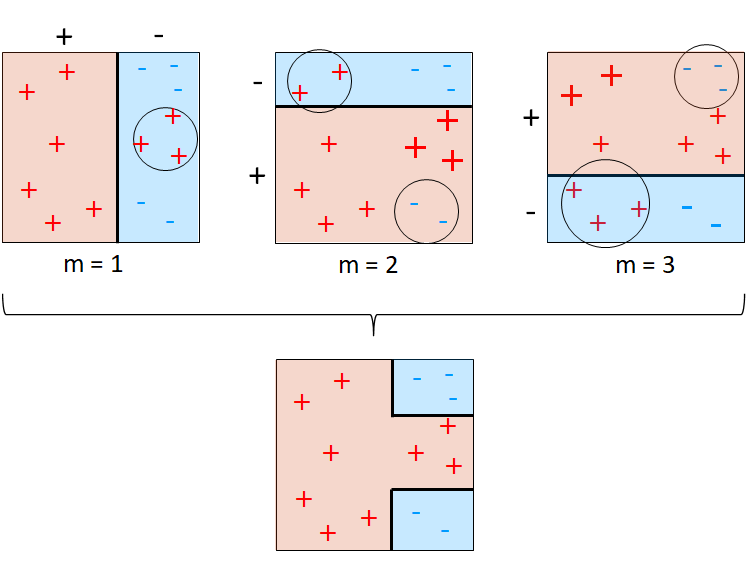
Figure 3 illustrates shows the training process of AdaBoost using a simple training set. As shown in the figure, the number of iterations is 3, hence the training process builds three base models. Initially, equal weight is assigned to each instance and the base model is trained in the usual manner. Then, the weights of the instances are adjusted so that the misclassified instances are given more importance in the next iteration. In iteration  , the three misclassified positive instances as indicated by the circle have their weights increased. This is shown by the size of those instances in iteration
, the three misclassified positive instances as indicated by the circle have their weights increased. This is shown by the size of those instances in iteration  . The same procedure is followed for iteration
. The same procedure is followed for iteration  .
.
We describe the formulation of AdaBoost for binary classification. Although AdaBoost was initially introduced for binary classification, it has been extended to multi-class classification and regression. In AdaBoost, the optimal weak model is solved using the exponential loss which is defined as follows.

Consider a dataset  where each target
where each target  . At iteration , we solve for the optimal weak model
. At iteration , we solve for the optimal weak model  and the corresponding weight which to be added to the ensemble model using the exponential loss.
and the corresponding weight which to be added to the ensemble model using the exponential loss.

Let  . Note that the term does not depend on
. Note that the term does not depend on  and
and  , but depends on the ensemble model
, but depends on the ensemble model  . Thus, we can assume
. Thus, we can assume  as the weight of instance
as the weight of instance  at iteration .
at iteration .

The expression can be written based on two cases: misclassification ( ) and correct classification (
) and correct classification ( ).
).

We can write  . Therefore, the above expression can be written as follows.
. Therefore, the above expression can be written as follows.

Assuming the instance weights have been normalized such that  . The normalization factor is a constant factor, hence it will not affect the minimization operation.
. The normalization factor is a constant factor, hence it will not affect the minimization operation.

From the above, since  is a positive value, we see that the weak base model
is a positive value, we see that the weak base model  to be added is
to be added is

We can see that this is actually the weighted error of the base model. Note that the base model doesn’t have to be strong. It is sufficient that the weighted error is less than 0.5.
Now, we need to solve for . Let’s us denote the weighted error as  . We substitute
. We substitute  into the expression.
into the expression.

We take the derivative with respect to , and then divide it by  .
.

Setting it to zero to solve for the minimum.

Therefore, the ensemble model is then updated

Recall that . The weights of the next iteration is

We can rewrite  . Thus, the weight update becomes
. Thus, the weight update becomes

Notice that the term  multiplies all the weights by the same value and it will be canceled out in the normalization step. Thus, it has no effect on the weight update and can be dropped.
multiplies all the weights by the same value and it will be canceled out in the normalization step. Thus, it has no effect on the weight update and can be dropped.
Putting everything together, the algorithm of AdaBoost is given below.
Initialize the instance weights  where
where  for to M
Train a base model using the weighted training set.
Compute
for to M
Train a base model using the weighted training set.
Compute  if
if  Compute
Compute 
 Set
Set  else
return
else
return  Return
Return ![\hat{f}(\mathbf{x}) = \texttt{sign}[\sum_{m=1}^M \alpha_m b_m(\mathbf{x})]](https://halimnoor.com/wp-content/ql-cache/quicklatex.com-bb1041cb962ffcfbaa54315351b3ecbb_l3.png "Rendered by QuickLaTeX.com")
Gradient Boosting
Gradient boosting is a generalized boosting algorithm that is based on gradient descent. Recall that gradient descent is used to approximate the function (predictive model) by minimizing the loss function. This is done by computing the gradients of the loss function with respect to the weights which are then used to update the weights. Using the same approach, we can search the same way over functions instead of the weights [2-3].
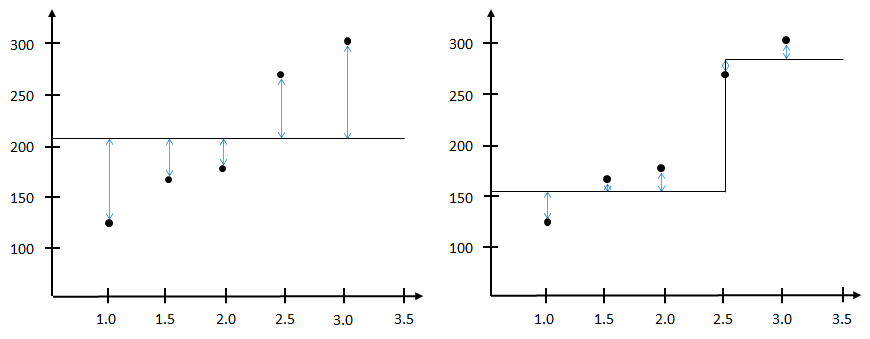
Consider a gradient boosting algorithm with steps. The algorithm begins with a random guessed function as the initial weak base model, which could be the average function as indicated by the black line in Figure 4. For each subsequent steps, we add a base model that will correct the error of its predecessor’s predictions. This is done by calculating the difference between the predictions and the true values as indicated by the blue line. The prediction error which is also known as residual, is then used as the target to train the base model and add it to the ensemble model. The reasoning behind this is that if we can approximate the residuals, we can use it to correct wherever errors it had made. This is shown in the figure on the right, the residuals have been reduced when the average function is added with the newly built base model.
We describe the formulation of gradient boosting for regression. Given a loss function

where  is the regression loss such as squared loss function and
is the regression loss such as squared loss function and  is the approximated function or the trained model. The aim is to minimize
is the approximated function or the trained model. The aim is to minimize  with respect to . Recall that in boosting, weak base models are sequentially added to produce an ensemble model. Thus, minimizing the loss function can be viewed as
with respect to . Recall that in boosting, weak base models are sequentially added to produce an ensemble model. Thus, minimizing the loss function can be viewed as

where  . The optimization problem is solved using gradient descent. At step , the gradient of
. The optimization problem is solved using gradient descent. At step , the gradient of  is
is
![g_m^i=[\frac{\partial L(y^i,\hat{f}(\mathbf{x}^i))}{\partial \hat{f}(\mathbf{x}^i)}]_{\hat{f}=\hat{f}_{m-1}}=-(y^i - \hat{f}(\mathbf{x}^i))](https://halimnoor.com/wp-content/ql-cache/quicklatex.com-f7d03f76067110497d04dc4c35681ece_l3.png "Rendered by QuickLaTeX.com")
We would like to reduce the residuals of the previous step. Thus the negative gradient is taken

Train  using the
using the  .
.

Finally, add to the ensemble model.

where is a constant value typically in the range of 0 and 1.
In practice, the base model is implemented a decision tree with a limited depth e.g. maximum depth of 3. Gradient boosting can be used for both regression and classification. For classification, the log loss (binary cross entropy) is used as the loss function. Putting everything together, the algorithm of gradient boosting is given below.
for to
Compute the gradient residual ![r_m^i = -[\frac{\partial L(y^i,\hat{f}(\mathbf{x}^i))}{\partial \hat{f}(\mathbf{x}^i)}]_{\hat{f}=\hat{f}_{m-1}}](https://halimnoor.com/wp-content/ql-cache/quicklatex.com-54ef529d6b122ef81031f405c95a3c46_l3.png "Rendered by QuickLaTeX.com") Train a base model which minimize
Train a base model which minimize  Update
Update  Return
Return 
References
[1] Y. Freund and R. E. Schapire, “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting,” Journal of Computer and System Sciences, vol. 55, no. 1, pp. 119–139, Aug. 1997, doi: 10.1006/jcss.1997.1504.
[2] J. H. Friedman, “Greedy Function Approximation: A Gradient Boosting Machine,” The Annals of Statistics, vol. 29, no. 5, pp. 1189–1232, 2001.
[3] J. H. Friedman, “Stochastic gradient boosting,” Computational Statistics & Data Analysis, vol. 38, no. 4, pp. 367–378, Feb. 2002, doi: 10.1016/S0167-9473(01)00065-2.