Artificial Intelligence and Machine Learning
Artificial intelligence (AI) is a field of study in computer science that focuses on developing machines which can behave intelligently. There are various approaches in AI design such as statistical (includes machine learning), symbolic, evolutionary computation etc.
Machine learning is a subset of AI, which focuses on a computer’s ability to learn from observations (data) of the world.
Deep learning is a subset of Machine Learning, which takes the idea one step further whereby the computer learns the pattern in the data without human intervention.
Machine Learning
Machine learning is about learning from data. For example, in a scenario where we are asked by a physician to build a system that can detect brain cancer or not in CT scan images. The physician needs to provide a set of images from different patients – the set of images is called a dataset. The dataset should contain images of brain cancer and images of normal brains. In addition to providing the data, the physician needs to “label” the images since we are not the domain expert – we would not know which images are brain with cancerous tumors and which images are not. With the dataset, we feed the images together with the labels to the computer with a machine learning algorithm to learn to detect brain cancer by “seeing” all the images as shown in Figure 1.
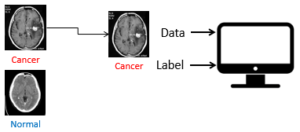
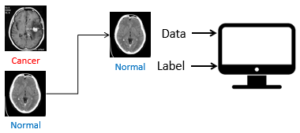
This process is repeated until the computer has learned from the data, and a “set of rules” will be produced which allows the computer to detect brain cancer in CT scan images. This set of rules is the predictive model. The predictive model can be used by the physician to assist him/her in analyzing new CT scan images and generate the prediction (cancer or no cancer). The process of learning from the data to produce the set of rules is known as “Training”. Using the predictive model to perform prediction on new data is known as “Testing”.
Machine learning was introduced way back in the 1950s. But the first formal definition (that I am aware of) was given by Tom Mitchell in his book Machine Learning, 1997 [1].
“A computer program is said to learn from experience 𝐸 with respect to some class of tasks 𝑇 and performance measure 𝑃, if its performance at tasks in 𝑇, as measured by 𝑃, improves with experience 𝐸.”
Based on the definition, we know that machine learning is a field of study that concerns algorithms that allow computers to automatically improve through experience. Using the above scenario, the experience is the database of CT scan images (with labels) and the task is the classification of the images into cancer or normal (no cancer). In order to know if the computer is improving with experience, we have to evaluate the performance of the image classification. Therefore, performance measure allows us to quantify the ability of the computer to perform the classification.
Why machine learning is needed? Do we need machine learning in every prediction problem? Machine learning is not needed if the data can be easily analyzed and predicted. For example, if we are asked to estimate (predict) the resale value of a car into Low, Medium and High given two factors, the car’s mileage and age. The rules to estimate the resale value could be as follows.
if Mileage < 100,000 Km and Age ≤ 10 years then Resale is High
if Mileage < 100,000 Km and Age > 10 years then Resale is Med
if Mileage ≥ 100,000 Km and Age ≤ 10 years then Resale is Med
if Mileage ≥ 100,000 Km and Age > 10 years then Resale is Low
The rules could be designed because there are two factors only. However, solving the problem becomes infeasible if more factors are added to the dataset. For example, could we design a set of rules that can accurately estimate the resale value given the following factors?
1. Mileage
2. Age
3. Maker and model
4. Year of manufacture
5. Horsepower
6. Transmission mode
7. Fuel type
8. Service records
9. Condition of interior
10. Condition of exterior
11. Accident history
12. Modification
The task of designing a robust set of rules is almost impossible. Even if it is possible, the task will be time-consuming, expensive and the model will be difficult to maintain. Note that normally, real-world datasets are of high dimensions, complex and noisy. In some cases, the data is unstructured e.g. image, time series and text which will increase the complexity of the system. For example, in the spam e-mail filter problem, the content of the e-mails needs to be analyzed and categorized into spam e-mail or non-spam email. One way to categorize the e-mails is to identify the words that can be considered as spam e.g. cash bonus, 100% free, extra income etc. in the e-mails. If any of the words are present, the e-mail is classified as spam e-mail. However, this method is not reliable and inaccurate because such e-mails may be spam to some users but others might find it be interesting. Human face recognition using a camera is another example which is infeasible to design the rules manually. To recognize human faces, the features of the faces such as the shape and/or size of nose, eyes and mouth need to be identified and extracted, and the combination of the features can inform us the person in the image. However, the number of feature combinations could thousands or even tens of thousands. Even if we can define all the rules, the combination may not be exhaustive which may lead to subpar performance.
Types of Machine Learning
In general, machine learning can be divided into three types: supervised learning, unsupervised learning and reinforcement learning. In supervised learning setting, the aim is to learn the mapping of the data (or the input) to the response of the data (or the output). For example, using the above scenario, given the CT scan images which is the data, we want to develop a mapping function (predictive model) that can do the mapping of the image to the image’s label which is either cancer or normal. Supervised learning works by searching for the optimal function among the many possible functions that best map between the inputs and output. This is done by making an assumption about the distribution of the data and fitting a function that best characterizes the data. Since the computer needs to learn the input-output mapping, each data in the dataset needs to be labeled. The labels allow the machine learning algorithm to guide its search for the optimal function.
In unsupervised learning setting, the label of the data is unavailable. Since the dataset is unlabeled, it is more widely and easily applicable than supervised learning. Data labeling is time-consuming, expensive and requires human experts. The goal of unsupervised learning is to find interesting patterns in the data and group the data into clusters. Typically, the grouping is performed based on the similarity of the data to each other. For example, given a dataset about customers, the clustering analysis of the customers could be based on their shopping behavior such as the kind of products that have been purchased, the average expenses and the average quantity per order. The outcome of the clustering analysis could be used for a targeted marketing campaign or to improve customer service operations.
Reinforcement learning is a type of machine learning that is less commonly used. It is an approach that allows computers to learn based on occasional reward and punishment. For example, consider a robot is learning to navigate through an environment to reach a destination. The robot explores the environment, and while exploring it might hit some obstacles and learn to avoid them. The process of learning is performed by rewarding the robot if it can avoid the obstacles and vice versa.
References
[1] T. M. Mitchell, Machine Learning, 1st edition. New York: McGraw-Hill Education, 1997.