Introduction
In some problems, the datasets that we are analyzing and modeling are of high dimensions. The high dimension refers to a large number of features that exist in the dataset which could be in the order of hundreds, thousounds or even tens of thousands. We might think that having an abundance of features is a good strategy because more feature means information for solving the problem. Unfortunately, that is not the case due to several reasons.
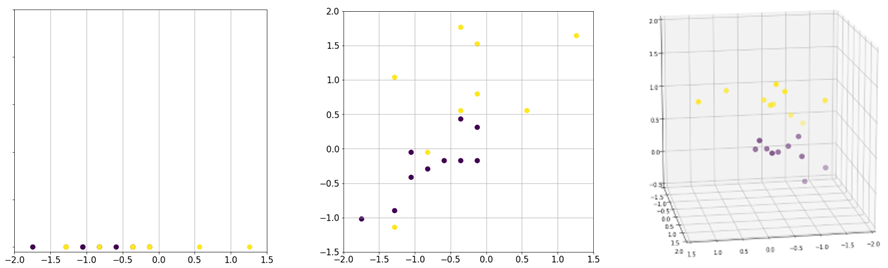
First, visualizing and analyzing a high-dimensional dataset to identify patterns and gain insights is difficult. For example, it is easier to visualize and analyze two-dimensional data than three-dimensional data. Beyond three dimensions, the analysis is more difficult and it is not possible to visualize the data. Second, some datasets may contain redundant features and features that are not relevant to solving the problem. These features should be removed because they do not add additional information to the prediction. Moreover, the features will incur unnecessary storage consumption and computation to the model training. Finally, the complexity of the problem and the machine learning models depends on the number of input dimensions as well as the number of instances. Although additional features may provide more information to the prediction, the volume of the feature space grows exponentially, thus the data becomes sparse. Figure 1 illustrates the issues of data sparsity. As we move from one dimension to three dimensions, there is more unoccupied space than the data points. As the number of dimensions grows, the data points appear to be equidistant and it becomes more difficult to cluster. Thus, given a high-dimensional dataset, the dataset should be analyzed to reduce it to a representation with lower dimensions.
Principal Component Analysis
Principal component analysis (PCA) is one of the most commonly used dimensionality reduction method. In PCA, the data in the original  -dimensional space is projected (or transformed) to
-dimensional space is projected (or transformed) to  -dimensional space, where
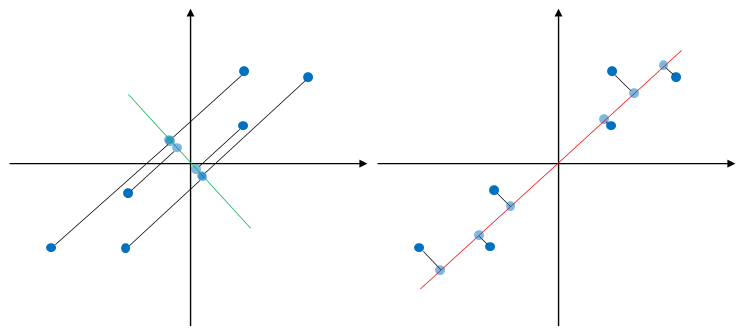
-dimensional space, where  . This is achieved by finding a hyperplane onto which to project the data. For simplicity, consider the data points in 2-d feature space as shown in Figure 2. The aim is to reduce the number of dimensions by projecting the data 1-d feature space. The figure shows two possible projections directions, one is onto a line in green color and the other one is onto a line in red color. The projected data points are indicated by blue circles. It can be seen that projecting data onto the green line results in overlapping data points while the red line results in data points that are scattered far away from each other. In other words, PCA seeks to find a direction in which to project the data that maximizes the variance of the data .
. This is achieved by finding a hyperplane onto which to project the data. For simplicity, consider the data points in 2-d feature space as shown in Figure 2. The aim is to reduce the number of dimensions by projecting the data 1-d feature space. The figure shows two possible projections directions, one is onto a line in green color and the other one is onto a line in red color. The projected data points are indicated by blue circles. It can be seen that projecting data onto the green line results in overlapping data points while the red line results in data points that are scattered far away from each other. In other words, PCA seeks to find a direction in which to project the data that maximizes the variance of the data .
Let’s consider the best solution for projecting 2-d data to 1-d data. The vector that represents the best solution (line) that the data is to be projected onto is  . The vector is known as the first principal component. Thus, the projection of data
. The vector is known as the first principal component. Thus, the projection of data  is defined by
is defined by

We want the projected data to have a maximum variance. Thus, we seek to find such that  is maximized subject to a constraint
is maximized subject to a constraint  , to ensure we obtain a unique solution. We rewrite the equation as follows:
, to ensure we obtain a unique solution. We rewrite the equation as follows:

where  is the covariance of . We restate the optimization problem by applying Lagrange multipliers.
is the covariance of . We restate the optimization problem by applying Lagrange multipliers.

Taking the derivative with respect to and setting it equal to zero.

Thus,  . We can see that is the eigenvector of and
. We can see that is the eigenvector of and  is the corresponding eigenvalue. Because we want to maximize
is the corresponding eigenvalue. Because we want to maximize  , we choose the eigenvector with the largest eigenvalue for the maximum variance.
, we choose the eigenvector with the largest eigenvalue for the maximum variance.
We can find the second vector  which is known as the second principal component. If the second component is solved, the 2-d dataset is not reduced, but transformed into a new 2-d representation. Note that the number of components that can be solved is equal to the number of dimensions of the data.
which is known as the second principal component. If the second component is solved, the 2-d dataset is not reduced, but transformed into a new 2-d representation. Note that the number of components that can be solved is equal to the number of dimensions of the data.
The second principal component should also maximize the variance, subject to  and
and  . We restate the problem by applying Lagrange multiplier.
. We restate the problem by applying Lagrange multiplier.
Taking the derivative with respect to and setting it equal to zero.

If we multiply the expression with

We know that  and
and  . Then, the expression becomes
. Then, the expression becomes  . Thus, we know
. Thus, we know  .
.
We can reduce to

where is the eigenvector and is the corresponding eigenvalue. Note that PCA is an unsupervised method in which it does not use the labels of the data. Thus, the resulting low dimesional representation may not be optimal for classification.
Solving for Eigenvectors and Eigenvalues
Suppose that

where covariance matrix of data points is defined by

where  .
.  is a
is a  vector of ones.
vector of ones.
Rewrite the above expression as follow:
 where
where  is an identity matrix
is an identity matrix
Solve  to obtain .
to obtain .
Substitute into to obtain  .
.
Numerical Example
Consider the following dataset

The mean of is

Mean normalize 

Calculate  where
where  . Note that
. Note that 


Find by solving  where
where 




 and
and 
 is the largest, hence the first principal component.
is the largest, hence the first principal component.
Substitute




Let  , thus
, thus 

The projected data 
Choosing Components
Total variance of the data is defined as

where  is the variance of component
is the variance of component  .
.
Explained variance is the ratio of variance of a principal component to the total variance,  . We choose where the cumulative explained variance is 0.95 – 0.99.
. We choose where the cumulative explained variance is 0.95 – 0.99.
References
[1] K. Pearson, “LIII. On lines and planes of closest fit to systems of points in space,” The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, vol. 2, no. 11, pp. 559–572, Nov. 1901, doi: 10.1080/14786440109462720.