Introduction
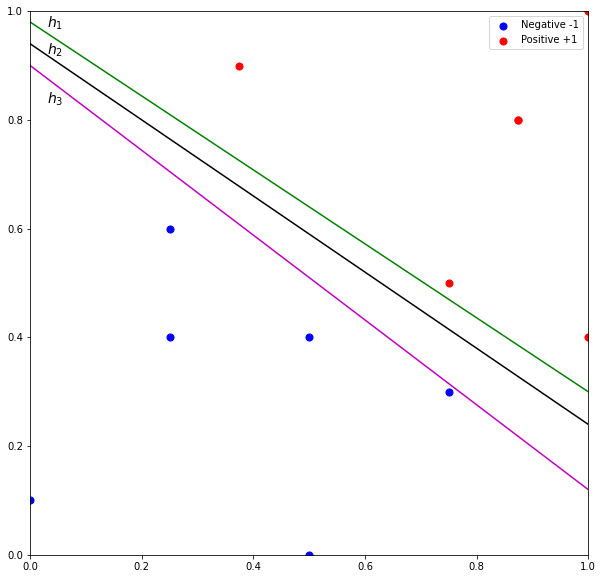
Perceptron seeks to find a hyperplane that can linearly separate the data points into their classes. But perceptron does not guarantee the hyperplane is the optimal solution. Figure 1 illustrates three possible solutions among an almost infinite number of possible hyperplanes. Although the hyperplanes perfectly separate the data points, misclassification could easily occur. For example, it is very likely for test points belonging to NEGATIVE class to be above hyperplane  . Similarly, test points belonging to POSITIVE class could appear below hyperplane
. Similarly, test points belonging to POSITIVE class could appear below hyperplane  . As for
. As for  , although the hyperplane appears to be a “better” hyperplane, the decision boundary is closer to POSITIVE class. Thus, the misclassification rate would increase especially for POSITIVE class.
, although the hyperplane appears to be a “better” hyperplane, the decision boundary is closer to POSITIVE class. Thus, the misclassification rate would increase especially for POSITIVE class.
Support vector machine (SVM) finds an optimal hyperplane that best separates the data points. This optimal solution is the hyperplane that is far away from the data points of both classes. To this end, SVM introduces the notion of margin which is illustrated in Figure 2. The margin is defined by the distance from the parallel dotted lines that are crossing the closest data points of both classes. The hyperplane is in the middle indicated by the blue line. The optimal hyperplane is the one that maximizes the margin of the training instances. The idea is if the margin is maximized, the hyperplane will be far away from the data points of both sides and reduce the chance of misclassification.
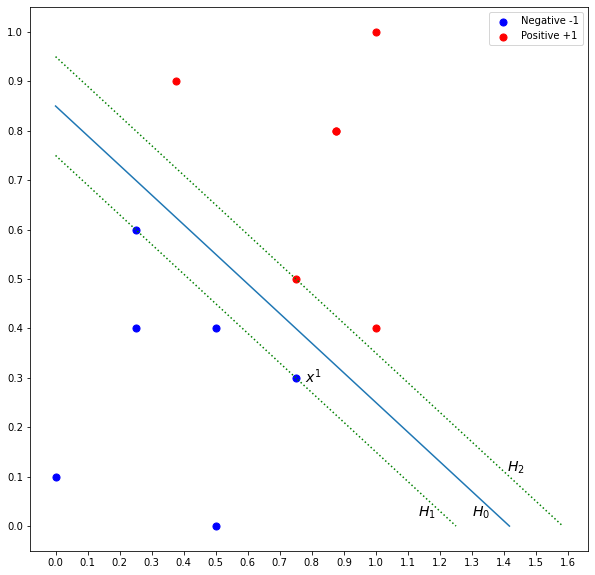
How do we find the margin? Given hyperplane  that separates the two classes, we know that is equidistant from hyperplane
that separates the two classes, we know that is equidistant from hyperplane  and
and  . is defined by
. is defined by

where  is the feature vector and
is the feature vector and  and
and  are the parameters of the hyperplane. For each instance
are the parameters of the hyperplane. For each instance  , we know that
, we know that
 for all
for all  belong to class
belong to class 
 for all belong to class
for all belong to class 
These are the constraints that need to be respected in order to select the optimal hyperplane. The first constraint states that all instances belonging to class must be above and the second constraint states that all instances belonging to class must be below . By not violating these constraints, we are selecting two hyperplanes (that define the margin) with no data points in between them. Let’s simplify the constraints. We multiply the first constraint on both sides with  .
.

We know that for all belonging to class , is . Thus, the constraint becomes

We do the same for the second constraint.

We know that for all belonging to class , is . Thus, the constraint becomes
Therefore, we can combine the two constraints as follows
for all instances .
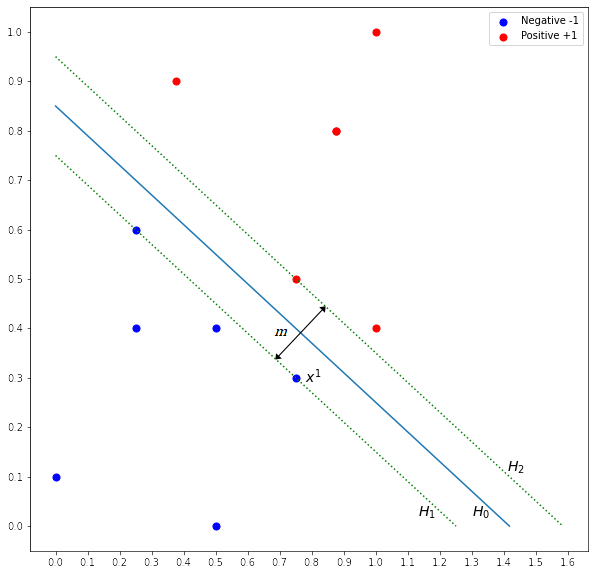
 is the margin as shown in Figure 3. We know that is a vector that is perpendicular to the hyperplanes. If the unit vector of is multiplied with , we get a vector
is the margin as shown in Figure 3. We know that is a vector that is perpendicular to the hyperplanes. If the unit vector of is multiplied with , we get a vector  , where it has the same direction as and with a distance equal to . Let the unit vector be
, where it has the same direction as and with a distance equal to . Let the unit vector be  , thus
, thus  .
.
We know that and are


Let  is a data point on . If we add with , the resultant is a point on .
is a data point on . If we add with , the resultant is a point on .

We can write as follows:




We know that  . We can rewrite the equation and solve for .
. We can rewrite the equation and solve for .


Therefore, margin is maximized when  is minimized. For mathematical convenience, we change from minimizing to minimizing
is minimized. For mathematical convenience, we change from minimizing to minimizing  .
.
 subject to
subject to  for
for 
You may skip the derivation of the solution and go to parameter solving.
We can solve the constrained optimization problem using quadratic programming [1]. Before that, we restate the optimization problem by applying Lagrange multiplier. Lagrange multiplier states that to find the maximum or minimum of a function  subjected to an equality constraint
subjected to an equality constraint  , form the following expression
, form the following expression  , set the gradient of to zero and find the Lagrange multiplier (parameter)
, set the gradient of to zero and find the Lagrange multiplier (parameter)  .
.

Substitute and .
 for all
for all  .
.
 .
.
Differentiate  with respect to
with respect to  and , and set it to zero
and , and set it to zero
 ,
, 
 ,
, 
Substitute and into and simplify it.


Thus, the optimization problem becomes as follows.
![\max_{\lambda} [\sum_{i=1}^{N} \lambda^i - \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda^i \lambda^j y^i y^j (\mathbf{x}^i)^T \mathbf{x}^j]](https://halimnoor.com/wp-content/ql-cache/quicklatex.com-a5440a292545b281c5875cd42f8676e5_l3.png "Rendered by QuickLaTeX.com")
subject to  and .
and .
As we can see above, the objective function now depends only on the Lagrange multipliers which is easier to be solved. Upon solving the optimization problem, most Lagrange multipliers ( ) will be zero, and only a few of them are non-zero. The data points with
) will be zero, and only a few of them are non-zero. The data points with  are called the support vectors [2]. These support vectors lie on the edge of the margin which define the margin and the optimal hyperplane.
are called the support vectors [2]. These support vectors lie on the edge of the margin which define the margin and the optimal hyperplane.
From the above, we see the solution for has the form

We can use any data point on the edge of the margin to solve . However, typically we use an average of all the solutions for numerical stability.

where  is the set of support vector indices. Given a test point
is the set of support vector indices. Given a test point  , the predicted value is
, the predicted value is

Soft Margin
Real-world data are typically noisy and not linearly separable. When the data are not separable, the algorithm above will not be able to produce the solution to the problem. To handle non-separable data, we relax the constraints by allowing data points within the margin. Consider the margin in Figure 4. Three data points are allowed to be within the margin. These “errors” need to be quantified as indicated by  and included in the constraints. The variable is known as slack variable. represents the amount of which the data points on the wrong side of the margin. If
and included in the constraints. The variable is known as slack variable. represents the amount of which the data points on the wrong side of the margin. If  , the data point is on the right side. If
, the data point is on the right side. If  , the data point is in the margin. If
, the data point is in the margin. If  , the data point is on the wrong side of the hyperplane.
, the data point is on the wrong side of the hyperplane.
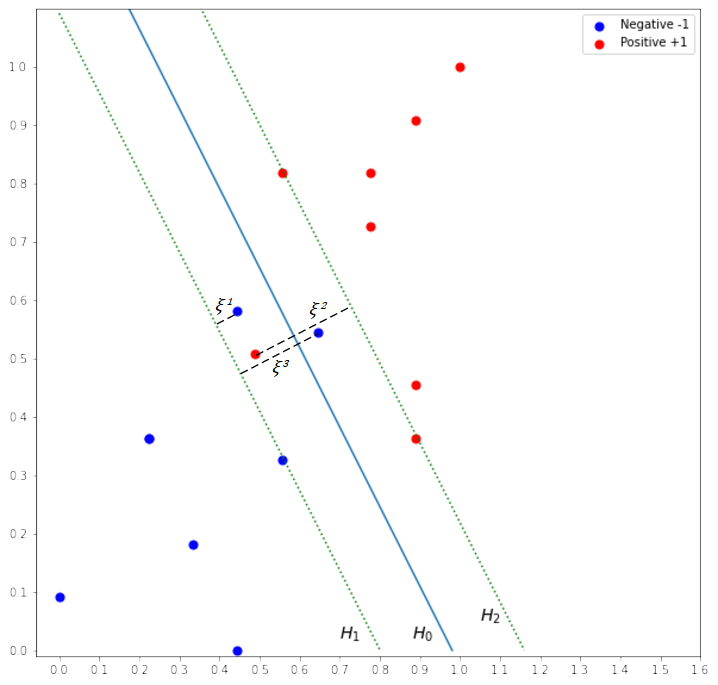
The combined constraint is now defined as follows:
 where
where  and
and
The equation (constraint) implies that we define an error if the prediction is on the wrong side of margin boundary. This is called the hinge loss. Given the prediction  , the loss function is defined as
, the loss function is defined as

By introducing the slack variables in the optimization problem, it is still possible to satisfy the constraint, albeit with some data points within or on the wrong side of the hyperplane. We add a term to the objective function which represents the total amount of which the data points on the wrong side of their margin.

subject to  and for
and for
where  is the regularization parameter to control the trade-off between maximizing the margin and minimizing the error. Small gives less importance to the error term, hence more mistakes are allowed, resulting in large margin. Conversely, large allows less mistakes resulting in small margin. You may skip the derivation of the solution and go to parameter solving.
is the regularization parameter to control the trade-off between maximizing the margin and minimizing the error. Small gives less importance to the error term, hence more mistakes are allowed, resulting in large margin. Conversely, large allows less mistakes resulting in small margin. You may skip the derivation of the solution and go to parameter solving.
Using Lagrange multiplier to formulate the optimization problem with respect to the Lagrange parameters.

where  is the Lagrange multiplier for constraint .
is the Lagrange multiplier for constraint .
Differentiate with respect to , and  , and set it to zero.
, and set it to zero.
,
,
 ,
, 
Since  , this implies
, this implies  .
.
Substitute the derivatives into and simplify it.
subject to and  .
.
Upon solving the optimization problem using quadratic programming, data points that lie on the correct side of the hyperplane, their corresponding , and the others have their  . Of these data points, the ones that lie on the edge of the margin have their
. Of these data points, the ones that lie on the edge of the margin have their  , and the rest lie within the margin with
, and the rest lie within the margin with  .
.
is computed as follows:
As before, we can use any data point on the edge of the margin to solve . However, typically we use an average of all the solutions for numerical stability.
where is the set of support vector indices. Given a test point , the predicted value is

Numerical Example
Consider the following dataset. Suppose  , a soft margin SVM is built by solving the optimization problem using quadratic programming. The lagrange multipliers are given as follows. Calculate parameter and .
, a soft margin SVM is built by solving the optimization problem using quadratic programming. The lagrange multipliers are given as follows. Calculate parameter and .





where 
Given a test point  , predict the test point using the SVM model.
, predict the test point using the SVM model.

Non-linear SVM with Kernel Trick
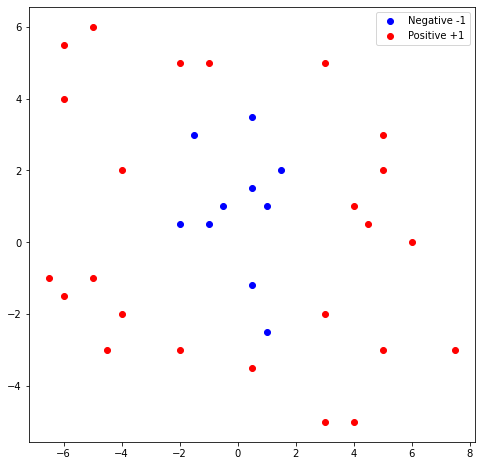
The algorithm we described above finds the linear model that divides the feature space. However, some real-world data is non-linear and a linear model will not be able to effectively classify the data as shown in Figure 5. As shown in the figure, no matter how we try to fit the linear model, the decision boundary will give a bad classification result. One way to deal with this kind of data is to extend the feature dimension by performing data transformation using basis functions such as polynomial and spline [3]. An example of non-linear transformation is given in Figure 5(bottom) whereby the polynomial basis function is used to map the data points from 2-dimension to 3-dimension. After the transformation, we can easily fit a linear model to separate the data points.
We select a basis function,  to transform each instance from
to transform each instance from  -dimension to -dimension where is generally much larger than . Then, the transformed dataset
-dimension to -dimension where is generally much larger than . Then, the transformed dataset  is used to fit the linear model
is used to fit the linear model 
The optimization problem of finding the optimal hyperplane has the same form except the constraints are defined in the new feature space.
subject to  and for
and for
Reformulate the problem using Lagrange multiplier.

subject to and .
Although the mapping of the features to a high dimensional feature space allows the data to be linearly separable, computing the transformation is expensive especially when the dimension is very high. This is because we have to apply the transformation on each sample followed by the inner product. The idea of the kernel trick is that the inner product between the transformed data is not needed. Instead, we require only the kernel function that allows us to operate in the high-dimensional space without computing the data transformation. Therefore, we just need to apply the kernel function,  directly in the original feature space to achieve the same effect.
directly in the original feature space to achieve the same effect.

Therefore,  is
is

subject to and . Given the set of support vector indices , can be solved

We use an average of all the solutions for numerical stability. Given a test point , the predicted value is calculate as follows:

Kernels
We discuss some of the commonly used kernel functions in the literature. Polynomial kernel function is defined as

where is degree parameter. Consider a dataset with two input features  and
and  and a polynomial kernel with a degree of 2.
and a polynomial kernel with a degree of 2.

We can see from the above that the dimension of the dataset is extended from 2 to 6.

Radial basis function (RBF) kernel function is similar to the pdf of the normal distribution. The kernel function is defined as

where  is the euclidean distance between the two data points and
is the euclidean distance between the two data points and  defines the spread of the kernel or the decision region of the support vectors. In other words, it determines how far the influence of a support vector in the prediction. A small value of means large decision region area while a large value of means small decision region area. Figure 6 shows the decision boundaries of non-linear SVM with polynomial and RBF kernels. The effect of is illustrated in Figure 7.
defines the spread of the kernel or the decision region of the support vectors. In other words, it determines how far the influence of a support vector in the prediction. A small value of means large decision region area while a large value of means small decision region area. Figure 6 shows the decision boundaries of non-linear SVM with polynomial and RBF kernels. The effect of is illustrated in Figure 7.
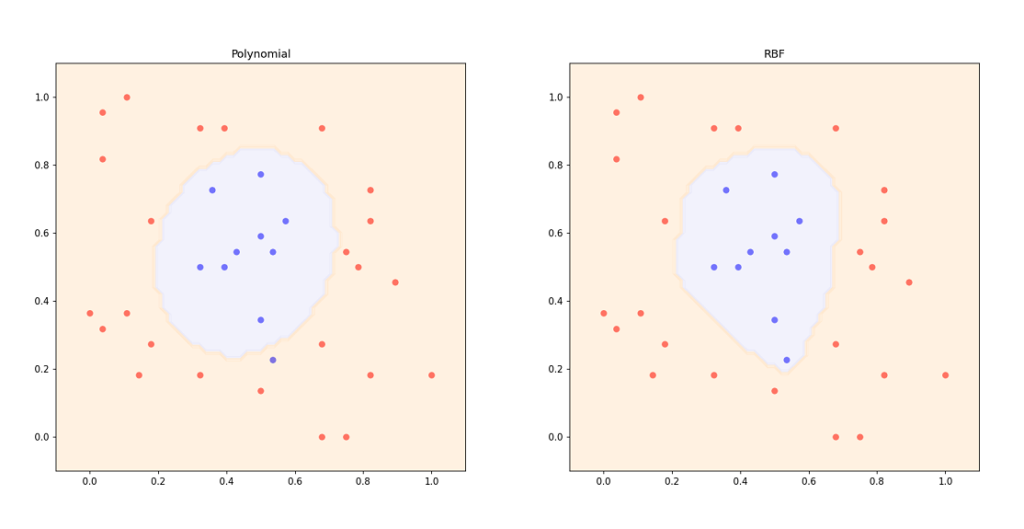
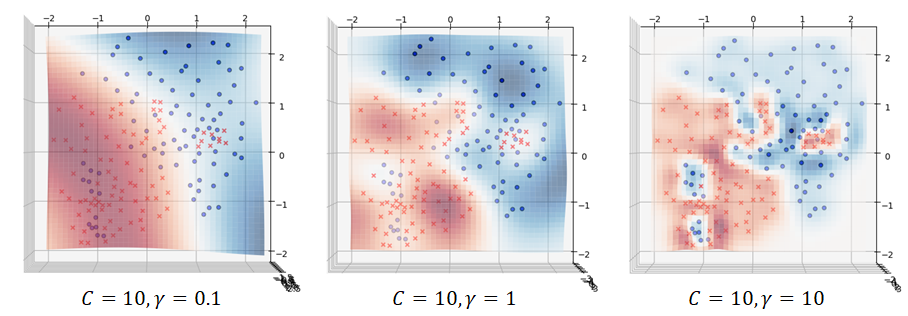
Numerical Example
Consider the following dataset. Suppose a non-linear SVM with RBF kernel and  is built by solving the optimization problem using quadratic programming. The lagrange multipliers are given as follows.
is built by solving the optimization problem using quadratic programming. The lagrange multipliers are given as follows.



All data points are support vectors since all  . Thus, support vector indices
. Thus, support vector indices  . Thus, can be solved as follows:
. Thus, can be solved as follows:
 ,
,  ,
,  ,
,  ,
,  ,
, 

Given a test point  , predict the test point using the SVM model.
, predict the test point using the SVM model.

Support Vector Regression
Support vector machine can be generalized for regression problems [4]. Similar to other regression models, support vector regression aims to fit the best line or hyperplane through the data points. However, in support vector regression, the best-fitted hyperplane is not a function that minimizes the error between the real and predicted value. Instead, support vector regression finds a hyperplane such that the margin has the most data points within it while fitting the error to be below a certain threshold  . In other words, the best-fitted line is the one that has at most deviation from the target of the training set.
. In other words, the best-fitted line is the one that has at most deviation from the target of the training set.
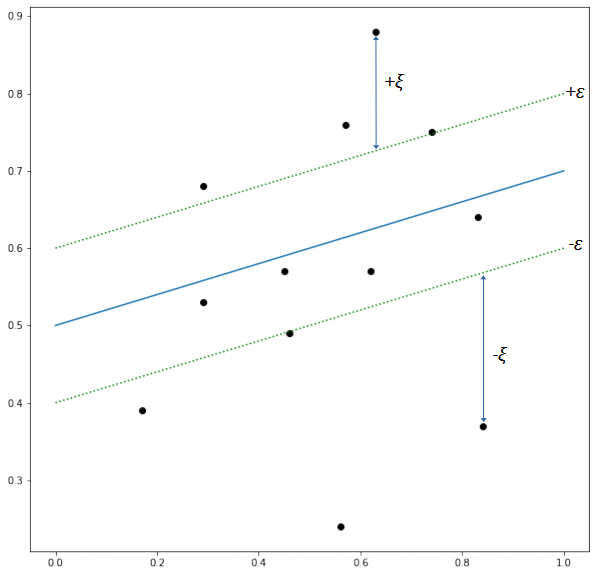
Figure 8 illustrates a support vector regression. The fitted line is indicated by the blue line and the boundary lines of the margin (also known as -tube) are indicated by the green dash lines. The error of the data points within the tube is tolerated (zero) while for data points that are outside the tube, the loss is the distance between the data points and the boundary lines. Thus, the loss function is defined as follows.

Similar to the soft margin hyperplane in support vector classification, the slack variables are introduced to represent the error of data points that are out of the ε-tube. Thus, the optimization problem is given as follows.
subject to  for
for 
Notice that there are two types of slack variables, for positive and negative errors to keep them positive. We restate the optimization problem by applying Lagrange multiplier.


Differentiate with respect to , and , and set it to zero.
, 
, 
 ,
, 
Substitute the derivatives into and simplify it.



subject to  .
.
Upon solving the optimization problem using quadratic programming, data points that lie within -tube have  . The support vectors have
. The support vectors have  or
or  , and we use them to calculate . The dot product
, and we use them to calculate . The dot product  can be replaced with a kernel
can be replaced with a kernel  and we can have a non-linear support vector regression.
and we can have a non-linear support vector regression.
References
[1] J. Nocedal and S. J. Wright, Numerical optimization. Springer, 1999.
[2] C. Cortes and V. Vapnik, “Support-vector networks,” Mach Learn, vol. 20, no. 3, pp. 273–297, Sep. 1995, doi: 10.1007/BF00994018.
[3] B. E. Boser, I. M. Guyon, and V. N. Vapnik, “A training algorithm for optimal margin classifiers,” in Proceedings of the fifth annual workshop on Computational learning theory, New York, NY, USA, Jul. 1992, pp. 144–152. doi: 10.1145/130385.130401.
[4] H. Drucker, C. J. Burges, L. Kaufman, A. Smola, and V. Vapnik, “Support vector regression machines,” Advances in neural information processing systems, vol. 9, 1996.